Description
With Scraper, you can have access to all of your competitor’s content in seconds. This allows you do deeper analysis using other plugins, such as OC Keyword Density, and find correlations in the content you likely wouldn’t have found otherwise.
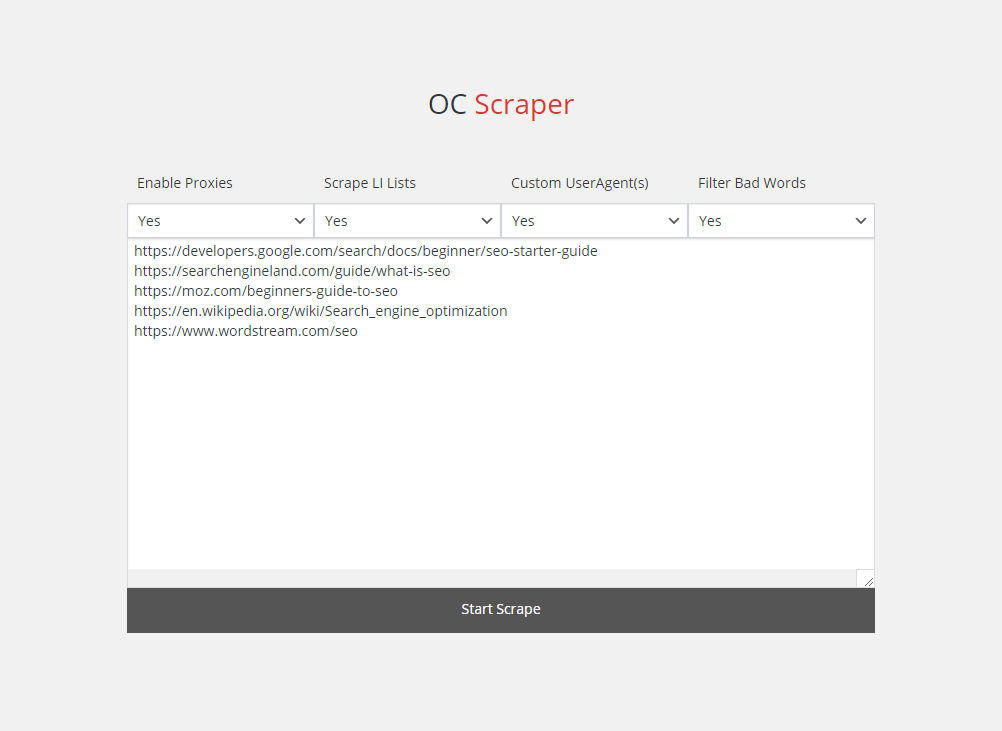
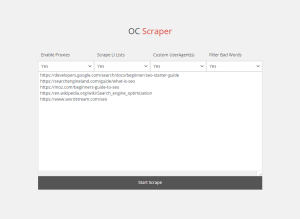
Enable Proxies
Having good proxies allows you to bypass many of the security methods put in place by websites, and dramatically reduces the chances of your IP being blocked from those websites. To enable proxies, go to Settings -> Enable Proxies, select “Yes,” enter a list of proxies into the box, and press Save Settings.
Scrape LI Lists
Although UL/LI lists exist in most legitimate content, they can cause a problem in certain scenarios. For example, if a site has a sidebar menu with hundreds of links wrapped in LI tags, it can result in the output having a bunch of unnecessary, boilerplate content. While you can use the “Bad Words” feature to filter this, sometimes it’s better to just drop LI tags from the scraping altogether. We recommend testing both with and without.
Custom UserAgent(s)
Using a custom UserAgent, you can replace PHP’s default, easy to identify UA with one that’s indistinguishable from a real human. Doing so will result in fewer failed scrape attempts and is highly recommended. On the settings page, you can enable this feature and list as many UA’s as you like. The scraper will randomly choose one for each scrape attempt.
Filter Bad Words
Sometimes during your scrapes, you may notice that there are various boilerplate words from menus, footers, and other non-essential areas of the website(s). Using Filter Bad Words, you can block these from appearing in the result. Anything you enter in the box will be filtered from the result.
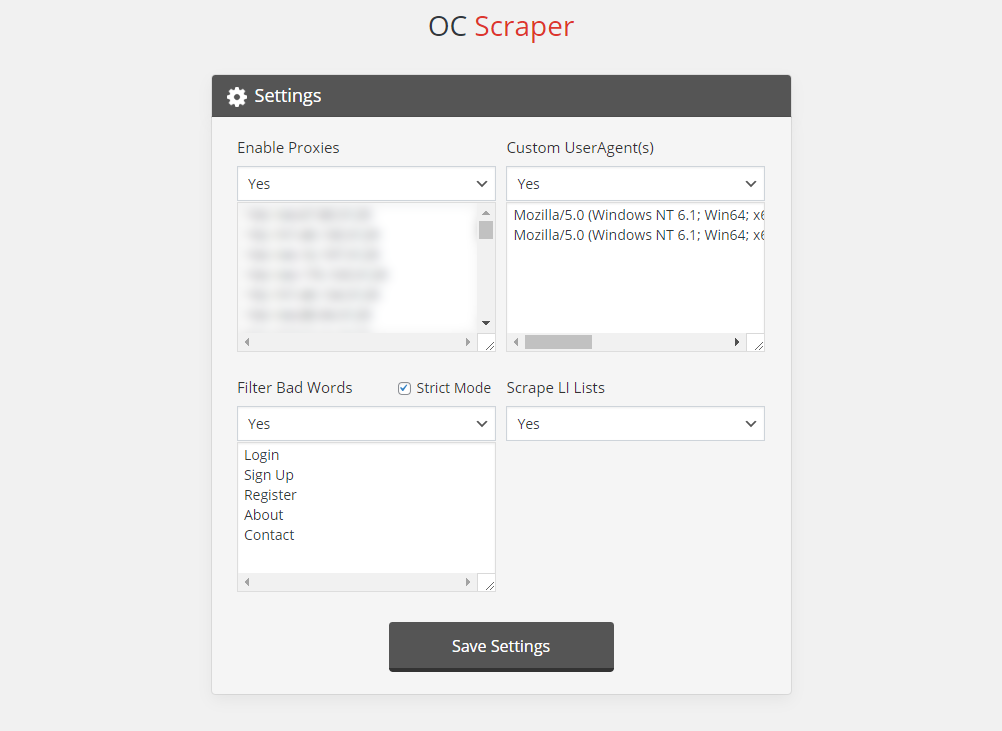
- Strict Mode – This mode requires you to enter the entire line of what you want to be filtered (for those familiar with regex – /^text$/).
- Regular Mode – This mode will filter anything found anywhere with the line/array of text. Avoid using commonly used words here, or too much of the output will be filtered out.
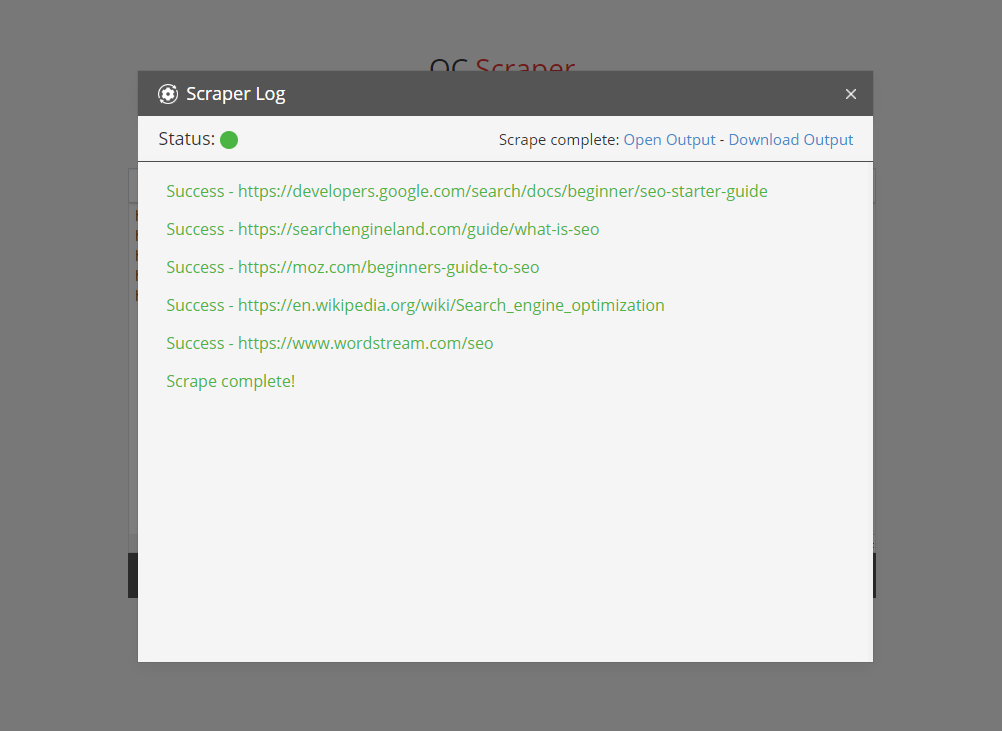
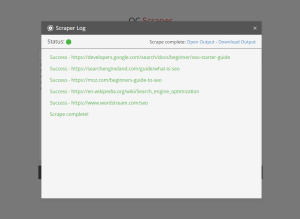
Output
There are two ways to access the results of the scrape. Once the scrape is finished, two links will appear near the top of the log, one which will directly open the .txt file in your browser, and another that will download it to your PC. You may notice the output file has a randomly generated number on the end. This is strictly for security reasons, to make it less likely anyone will find the file. Each time a scrape is performed, the previous output file is removed.
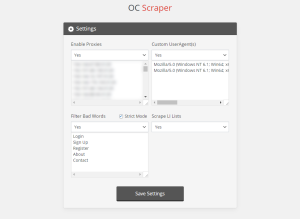
Settings Page
The settings page is pretty straightforward, but it should be noted that when you save settings on this page, they will appear the same on the main Scraper page. You can still change the settings in real-time on the main page, but we recommend saving them here beforehand.
Questions
Can I use this plugin on unlimited WordPress installs?
Yes. After purchasing the plugin, you can use it on as many WordPress installs as you like.
What are the requirements to use this plugin?
Your server must be running at least PHP 5.6+, and must have Allow URL Fopen enabled. Allow URL Fopen is generally considered safe, and is pretty easy to enable through cPanel, click here to learn how.
What is an example of a way to use this plugin?
There are many reasons to scrape content, it really all depends on your intentions. For competitive analysis, you can scrape the top X results of your target keyword, then compare their keyword densities to yours using a plugin like OC Keyword Density. For those on the darker side of things, you can scrape content, then use it to generate your own content. These are just a few examples, but there are countless other reasons why one may want to scrape content.